아이템 78 - 공유 중인 가변 데이터는 동기화해 사용하라
왜 동기화를 배워야 하나?
스레드는 여러 활동을 동시에 수행할 수 있게 해줍니다. 여러 활동을 동시에 처리한다면 당연히 더 빠르게 처리할 수 있습니다. 오늘날 어디서나 쓰이는 멀티 코어 프로세서의 힘을 제대로 활용하려면 반드시 동시성의 개념을 배워야 합니다.
동기화란?
프로세스나 스레드들이 서로 알고있는 공유중인 데이터가 같은 것을 의미합니다. 멀티 코어 프로세서의 힘을 제대로 활용하려면 멀티스레드 프로그래밍을 해야하며 여러 스레드가 동시에 접근하는 만큼 동기화에 주의를 기울여야 합니다.
동기화는 2가지 기능을 제공합니다.
- 배타적 실행 : 현재 사용중인 스레드만 접근이 가능하고, 다른 스레드가 접근하지 못하게 한다
- 일관성이 깨진 상태를 볼 수 없게 합니다. 항상 일관성이 지켜진 상태로 있게 합니다.
- 스레드 사이 안정적인 통신 : 어떤 스레드가 변경한 데이터를 다른 스레드에서 읽을 수 있게 한다
- 변경된 데이터의 최종 결과값을 읽을 수 있게 한다는 의미입니다.
동기화를 하는 방법을 알기 전에 책에서 궁금한 점을 먼저 짚고 가겠습니다.
자바 언어는 long과 double을 제외한 변수를 읽고 쓰는 동작이 원자적이다?
책에 보시면 “언어 명세상 long과 double 외의 변수를 읽고 쓰는 동작은 원자적(atomic)이다”라는 뜻이 나옵니다.
읽고 쓰는 동작이 원자적(Atomic)이라는 뜻은 여러 스레드가 같은 변수를 동기화없이 수정하는 중이라도, 어떤 스레드가 정상적으로 저장한 값을 온전히 읽어오는 것을 보장한다는 의미입니다.
엥? 그러면 원자적 데이터를 읽고 쓸 때는 동기화를 하지 않아도 되나?
아닙니다.
스레드가 필드를 읽을 때 항상 수정이 반영된 값을 얻는다고 보장하지만, ‘한 스레드가 저장한 값이 다른 스레드에게 보이는가’는 보장하지 않습니다.
즉, 다른 스레드가 필드를 보고나서 읽을텐데 보이는 걸 보장하지 않는다는 뜻입니다. 결국 원자적 데이터라도 수정된 필드를 보고 읽기 위해서는 동기화의 안정적인 통신이 필요합니다.
왜 long과 double은 원자적이지 않나?
같은 primitive 타입인데 long과 double은 원자적이지 않을까요?
그 이유는 CPU가 처리하는 기본 단위인 워드보다 길이가 길기 때문입니다.
CPU를 고르실 때 32bit(x86), 64bit(x64) 를 보신 적 있으실 겁니다. 이때 말하는 32bit, 64bit가 CPU의 기본 단위인 워드를 뜻합니다.
java에서 long과 double을 생각해보세요. long과 double 모두 8바이트로 64bit입니다. 보통 컴퓨터에서 4바이트를 1 워드로 사용했었고 JVM도 보통 4바이트를 1 워드로 사용한다고 합니다.
즉, JVM = 4바이트이며 long과 double = 8바이트이기 때문에 메모리 할당을 한번에 해줄 수 없어 원자적이지 못합니다.
참고로 JVM도 종류가 많아서 종류에 따라 메모리 할당하는 바이트가 다릅니다.
동기화 방법 및 예시
Thread 2개로 1억을 만드는 예시 (해당 글 참고)
sum 변수가 인스턴스 변수로 공유되고 있습니다. 이 상태에서 두 개의 스레드를 만들어서 1억을 만들어야 합니다.
실제로 돌려보면 2개의 스레드가 공유변수를 건드리기 때문에 1억이 나오지 않고 매번 다른 값이 나오게 됩니다.
참고로 여러 스레드가 같은 공유 메모리에 write하는 행위를 전문적인 용어로 Data Race라고 합니다. 저희들은 이 행위를 막아야 합니다.
어떻게 하면 Data Race를 막을 수 있을까요? 여러 가지 방법이 있습니다.
- 임계영역을 줄 수 있는 synchronized 키워드를 사용한다
- Atomic 패키지를 사용해 Lock을 쓰지 않고 sum += 2 부분을 Atomic하게 만든다
- 피터슨 알고리즘을 이용해 직접 Lock 알고리즘을 만든다
예시를 통해서 알아보겠습니다.
private int sum = 0;
@DisplayName("1억이 아닌 매번 다른 값이 나온다")
@Test
void name() throws InterruptedException {
Thread thread1 = new Thread(this::workerThread);
Thread thread2 = new Thread(this::workerThread);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
assertThat(sum).isNotEqualTo(100_000_000);
}
private void workerThread() {
for (int i = 0; i < 25_000_000; i++) {
sum += 2; // Data Race가 발생한다
}
}
synchronized
공유변수를 건드리는 쪽에 synchronized 키워드를 붙이면 객체가 가진 고유 락(Intrinsic Lock)으로 동시성 문제를 해결할 수 있습니다.
private int sum = 0;
@DisplayName("2개의 스레드로 1억을 만들기, synchronized을 이용해 Lock")
@Test
void twoThreadSumWithSynchronized() throws InterruptedException {
Thread thread1 = new Thread(this::workerThreadWithSynchronized);
Thread thread2 = new Thread(this::workerThreadWithSynchronized);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
assertThat(sum).isEqualTo(100_000_000);
}
private synchronized void workerThreadWithSynchronized() {
for (int i = 0; i < 25_000_000; i++) {
sum += 2;
}
}
volatile
이 키워드는 Data Race를 해결해주진 않지만 스레드 중 하나만 write 하고 다른 스레드들은 read할 때 해결책으로 쓰일 수 있습니다.
평소에 선언하던 것처럼 volatile 키워드가 없이 선언하면 CPU Cache에 저장된 값이 읽어지는데 이러면 각각의 스레드가 각 CPU Cache에 저장된 값이 다르기 때문에 읽는 변수의 값이 다른 문제가 발생합니다.
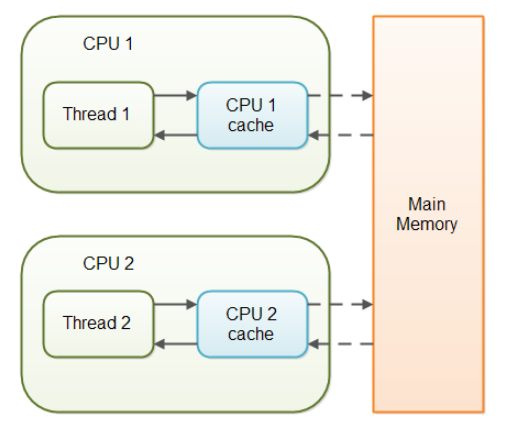
volatile 키워드를 선언하면 해당 변수를 메인 메모리에 저장하겠다라는 걸 명시하게 됩니다. 해당 변수를 메인 메모리에 저장하고 메인 메모리에서 읽어오기 때문에 항상 최근에 기록된 값을 읽게 됨을 보장합니다.
그러나 위와 예시와 같이 여러 스레드가 증가 연산자(++)처럼 필드를 읽고 수정하는 연산을 한다면 volatile 키워드를 선언해도 두 번째 스레드가 비집고 들어와서 새로운 값을 저장해버릴 수 있습니다.
또한 CPU Cache보다 메인 메모리에 접근하는 비용이 더 크기 때문에 성능도 좋진 않습니다.
즉, volatile 키워드는 하나의 스레드만 write하고 나머지 스레드는 read하는 상황에서 사용해야 하며 성능도 잘 생각해야 합니다.
Atomic 패키지
atomic 패키지를 사용하면 정수 값들을 동기화시킬 수 있습니다. Atomic은 CAS라는 알고리즘을 사용하는데요. 이 알고리즘은 메모리에 저장된 값과 CPU Cache에 저장된 값을 비교해 동일한 경우에만 update를 수행합니다. 그래서 volatile 키워드가 가지고 있던 단점을 커버하며 성능도 좋습니다.
private AtomicInteger atomicSum = new AtomicInteger();
@DisplayName("2개의 스레드로 1억을 만들기, AtomicInteger를 이용 (Lock이 아님)")
@Test
void twoThreadSumWithAtomic() throws InterruptedException {
Thread thread1 = new Thread(this::workerThreadWithAtomic);
Thread thread2 = new Thread(this::workerThreadWithAtomic);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
assertThat(atomicSum.get()).isEqualTo(100_000_000);
}
private void workerThreadWithAtomic() {
for (int i = 0; i < 25_000_000; i++) {
atomicSum.addAndGet(2);
}
}
피터슨 알고리즘
2개의 스레드일 때 boolean값 flag를 직접 만들어서 Lock을 걸어줄 수 있는 피터슨 알고리즘이라는 게 있습니다. 즉, 스레드마다 flag를 가지고 있도록 하고 계속 while문을 돌려서 해당 임계 구역이 사용가능한 구역인지 확인하는 알고리즘입니다.
그러나 현재의 CPU는 순차적으로 스레드를 실행시키지 않아서 피터슨 알고리즘이 먹히지 않는다고 합니다. 피터슨 알고리즘과 같이 일반적인 프로그래밍 방식으로는 멀티 스레드에서 안정적으로 돌아가는 프로그램을 만들 수 없습니다.
번외 - Thread의 join()
join 메서드를 사용하면 join 메서드를 호출한 스레드는 join한 스레드가 종료될 때까지 대기합니다.
아래 예제에서 join을 사용했을 때 newThread1, newThread2가 종료될 때까지 mainThread가 대기하게 됩니다.
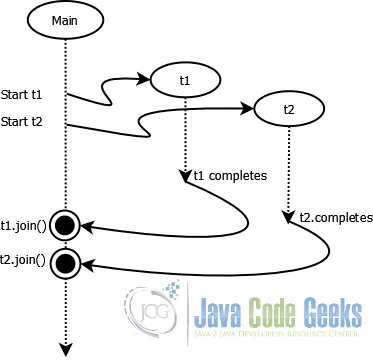
@DisplayName("join을 하지 않은 thread, 계속 살아있으며 main Group")
@Test
void notJoinedThread() {
Thread mainThread = Thread.currentThread();
Thread newThread1 = new TimerThread(1);
Thread newThread2 = new TimerThread(1);
newThread1.start();
newThread2.start();
assertThat(mainThread.getId()).isGreaterThan(0L);
assertThat(mainThread.getName()).isEqualTo("Test worker");
assertThat(mainThread.getThreadGroup().getName()).isEqualTo("main");
assertThat(mainThread.isAlive()).isTrue();
assertThat(newThread1.getId()).isGreaterThan(0L);
assertThat(newThread1.getThreadGroup().getName()).isEqualTo("main");
assertThat(newThread1.getName()).contains("Thread-");
assertThat(newThread1.isAlive()).isTrue();
assertThat(newThread2.getId()).isGreaterThan(0L);
assertThat(newThread2.getThreadGroup().getName()).isEqualTo("main");
assertThat(newThread2.getName()).contains("Thread-");
assertThat(newThread2.isAlive()).isTrue();
}
@DisplayName("join한 thread, 각 스레드는 실행이 완료되면 죽고 Group이 null임")
@Test
void joinedThread() throws InterruptedException {
Thread mainThread = Thread.currentThread();
Thread newThread1 = new TimerThread(1);
Thread newThread2 = new TimerThread(1);
newThread1.start();
newThread2.start();
newThread1.join();
newThread2.join();
assertThat(mainThread.getId()).isGreaterThan(0L);
assertThat(mainThread.getName()).isEqualTo("Test worker");
assertThat(mainThread.getThreadGroup().getName()).isEqualTo("main");
assertThat(mainThread.isAlive()).isTrue();
assertThat(newThread1.getId()).isGreaterThan(0L);
assertThat(newThread1.getThreadGroup()).isNull();
assertThat(newThread1.getName()).contains("Thread-");
assertThat(newThread1.isAlive()).isFalse();
assertThat(newThread2.getId()).isGreaterThan(0L);
assertThat(newThread2.getThreadGroup()).isNull();
assertThat(newThread2.getName()).contains("Thread-");
assertThat(newThread2.isAlive()).isFalse();
}
static class TimerThread extends Thread {
public int count;
TimerThread(int count) {
this.count = count;
}
@Override
public void run() {
try {
Thread.sleep(count * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
요약
동기화는 두 가지를 제공한다
- 현재 사용중인 스레드만 접근이 가능하고, 다른 스레드가 접근하지 못하게 한다
- 어떤 스레드가 변경한 데이터를 다른 스레드에서 읽을 수 있게 한다
여러 스레드가 가변 데이터를 공유한다면 그 데이터를 읽고 쓰는 동작은 반드시 동기화하자
객체의 필드를 동기화하는데 많은 방법이 있으나 Lock을 최소화하기 위해 Atomic 패키지를 활용하자
출처
- 이펙티브 자바 3판
- https://arcsit.tistory.com/entry/Thread-동시성-프로그래밍
- https://www.slideshare.net/naihoonjung/naver-3
- https://www.slideshare.net/zzapuno/kgc2013-3
- https://www.zehye.kr/ios/2020/03/08/12iOS_thread/
- https://lena-chamna.netlify.app/post/concurrency_programming_thread_and_queue/
- https://stackoverflow.com/questions/517532/writing-long-and-double-is-not-atomic-in-java/517539
- https://nesoy.github.io/articles/2018-06/Java-volatile
- https://examples.javacodegeeks.com/core-java/threads/java-thread-join-example/